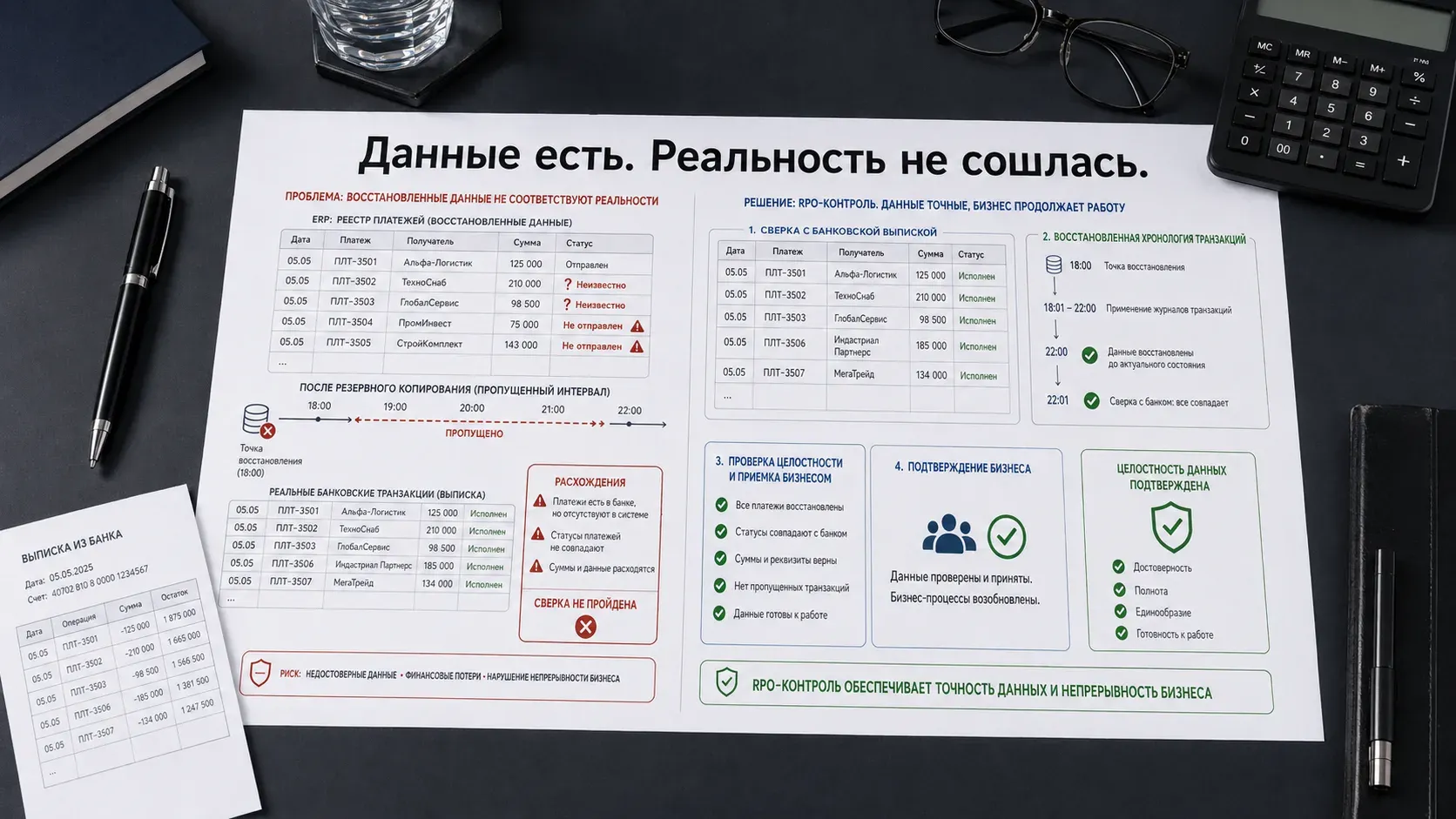
Система поднялась. Данные восстановлены. Открыли раздел исходящих платежей - десятки позиций со статусом "не отправлен". Но деньги с расчётного счёта уже ушли. Платежи прошли после 16:00. Копия была снята до этого момента. В системе эти часы не существуют.
Это не технический сбой. Это неправильно выбранная точка восстановления. И именно здесь начинается разговор про RPO.
Два типа потери данных
В большинстве компаний о потере данных думают в одном варианте: данных нет. Сервер упал, файлы недоступны, нужно восстанавливать. Это видно сразу. Понятно, что делать.
Второй тип потери данных опаснее именно потому, что его не видно.
Система работает. Данные есть. Отчёты формируются. Только все эти данные описывают бизнес на час, два или день раньше текущего момента. Транзакции, которые прошли после снятия копии, в системе не существуют. Пользователи работают, вводят данные, принимают решения - и часть из этих решений опирается на картину, которая уже устарела.
Этот разрыв не бросается в глаза. Его нужно специально искать.
Здесь нужно развести два понятия. RPO не обещает, что при сбое не исчезнет ни одной строки. RPO - Recovery Point Objective - показывает максимальный временной разрыв, который может появиться после технического восстановления. Это управленческое решение: какой период потери операций бизнес считает допустимым при сбое.
А 0 потерь данных - это уже итоговый бизнес-вердикт: все операции найдены, сверены, довнесены и приняты владельцами процессов. Без этой приёмки "0 потерь" - не результат, а предположение.
Как мы обнаружили потерю
После восстановления открыли реестр исходящих платежей. Десятки позиций со статусом "не отправлен". При этом выписка с расчётного счёта показывала обратное: деньги ушли.
Стали разбираться. Платежи отправлялись после 16:00. Резервная копия для восстановления была снята до этого момента. Несколько часов реальных транзакций в системе отсутствовали - система просто не знала, что они были.
Ситуация создавала реальную управленческую вилку. Заплатить повторно - риск задвоения, с которым потом придётся разбираться с каждым поставщиком отдельно. Не платить - риск пропустить дедлайн, получить штраф или сорвать поставку. В день проходят десятки платежей, и по каждому нужно понять: он реально ушёл из банка или остался только в системе. Разбираться вручную, пока дедлайн не прошёл - именно так выглядит цена потери нескольких часов данных.
Это и есть цена неправильно выбранного RPO. Не "данных нет". А "данные есть в другом месте, их надо найти и сверить вручную" - под давлением времени и с неизвестным исходом по каждой позиции.
До этого момента в компании не было формального ответа на вопрос, какой период потери данных считать допустимым. Бэкапы делались по расписанию, но расписание никто не сверял с реальным ритмом бизнес-операций. Платежи после 16:00 - это была обычная операционная реальность, которую никто не учёл при выборе времени снятия копии.
RPO как управленческое решение
После этого я перестал принимать расписание бэкапов как технический факт. Мы разобрали критичные контуры по реальному операционному ритму - и для каждого зафиксировали отдельный RPO с владельцем и контрольной точкой проверки.
Для каждого контура поставили вопрос прямо: сколько операций за какой период бизнес готов восстанавливать вручную при сбое? Ответ превратился в требование к частоте резервного копирования.
Для критичных контуров - товародвижение, финансы, зарплата - зафиксировали RPO в один час. Данные в ЦОД уходят каждый час. В согласованных сценариях восстановления максимальный автоматический разрыв - один час операций. Всё, что попадает в этот разрыв, должно восстанавливаться из внешних источников: банковские выписки, данные ОФД, первичные документы, журналы обменов. И принимается бизнесом.
Для некритичных систем - один день. Там ритм операций другой, и однодневная потеря не создаёт критичных последствий.
Разница принципиальная: раньше RPO не существовал как решение. Теперь он зафиксирован, понятен, привязан к реальному операционному ритму и проверяется на каждом тесте.
Что проверяли при приёмке данных
Контрольные сверки после восстановления охватывали все показатели - в деньгах и в штуках, по всем точкам учёта.
Исходящие платежи, входящие оплаты, остатки, движение товара, заказы. По каждой торговой точке, по каждому типу операций.
Приёмка данных отвечает не на вопрос "отчёт открылся", а на четыре других: за какой период сверяем, с каким внешним источником сравниваем, кто подтверждает корректность и какое расхождение блокирует закрытие восстановления. Пока нет ответов на все четыре - восстановление не завершено.
Причина полного охвата: ошибка в данных может быть локальной. Один тип операций, один временной интервал, одна торговая точка. Выборочная проверка такую ошибку пропустит. Случай с платежами это показал: проблема была в конкретном временном интервале, а не в системе в целом. Без полной сверки с банковской выпиской нашли бы не сразу - или не нашли бы до первого звонка от поставщика.
Кто принимает "данные восстановлены корректно"
Те же сотрудники, назначенные от владельцев ключевых процессов, что проводят бизнес-приёмку после восстановления систем. Но с другой задачей.
При приёмке систем они проверяют: бизнес-процессы работают, транзакции проходят, система отвечает корректно. Это вопрос работоспособности.
При приёмке данных вопрос другой: показатели сошлись, расхождений нет, статусы платежей соответствуют банковской выписке, данные актуальны на ожидаемый момент времени. Это вопрос целостности.
Два разных вопроса. Два разных вердикта. Восстановление считается завершённым только после обоих.
ИТ не может дать вердикт по целостности данных самостоятельно - для этого нужен тот, кто знает, как должна выглядеть корректная картина в конкретном бизнес-контексте. Именно поэтому бизнес участвует в приёмке, а не просто получает уведомление о завершении восстановления.
У этого решения тоже есть цена
RPO в один час для критичных систем - это постоянная операционная нагрузка.
Репликация каждый час требует ежедневного контроля: данные действительно уходят, канал работает, нет пропусков. Контрольные сверки после каждого теста восстановления - это время назначенных сотрудников. Сами сотрудники должны понимать, что именно проверять и как интерпретировать расхождения.
Если дисциплина проседает - RPO становится декларацией, а не гарантией. Формально в документе написано "один час". Фактически последний работающий тест был три месяца назад, а канал репликации тихо упал две недели назад и никто не заметил.
Решение рабочее. Но у него есть цена: постоянный мониторинг, регулярные тесты и ответственные, которые реально понимают, что делают.
Для собственника
Вопрос "у нас есть бэкапы" - не тот вопрос.
Правильные три вопроса: какие данные и за какой период мы реально умеем восстановить в проверенных сценариях сбоя? Кто это проверил последний раз? Когда был последний тест, который подтвердил этот ответ?
Если на любой из трёх нет чёткого ответа - RPO есть только на бумаге.
Для CEO
0 потерь данных - это не характеристика оборудования и не свойство облачного провайдера.
Это результат трёх управленческих решений: правильно выбранный RPO под реальный операционный ритм бизнеса, регулярные тесты, которые подтверждают, что параметр выполняется, и бизнес-приёмка после каждого восстановления, которая проверяет целостность, а не только работоспособность.
Без любого из трёх - оставшиеся два не дают гарантии.
0 потерь данных - это не свойство бэкапа. Это дисциплина RPO, сверок и тестов. Без бизнес-приёмки компания не знает, что именно она восстановила.
DR-контур выстроен. В следующих материалах - как управлять изменениями в ИТ, которые этот контур и весь бизнес поддерживают.
#cio #итибизнес