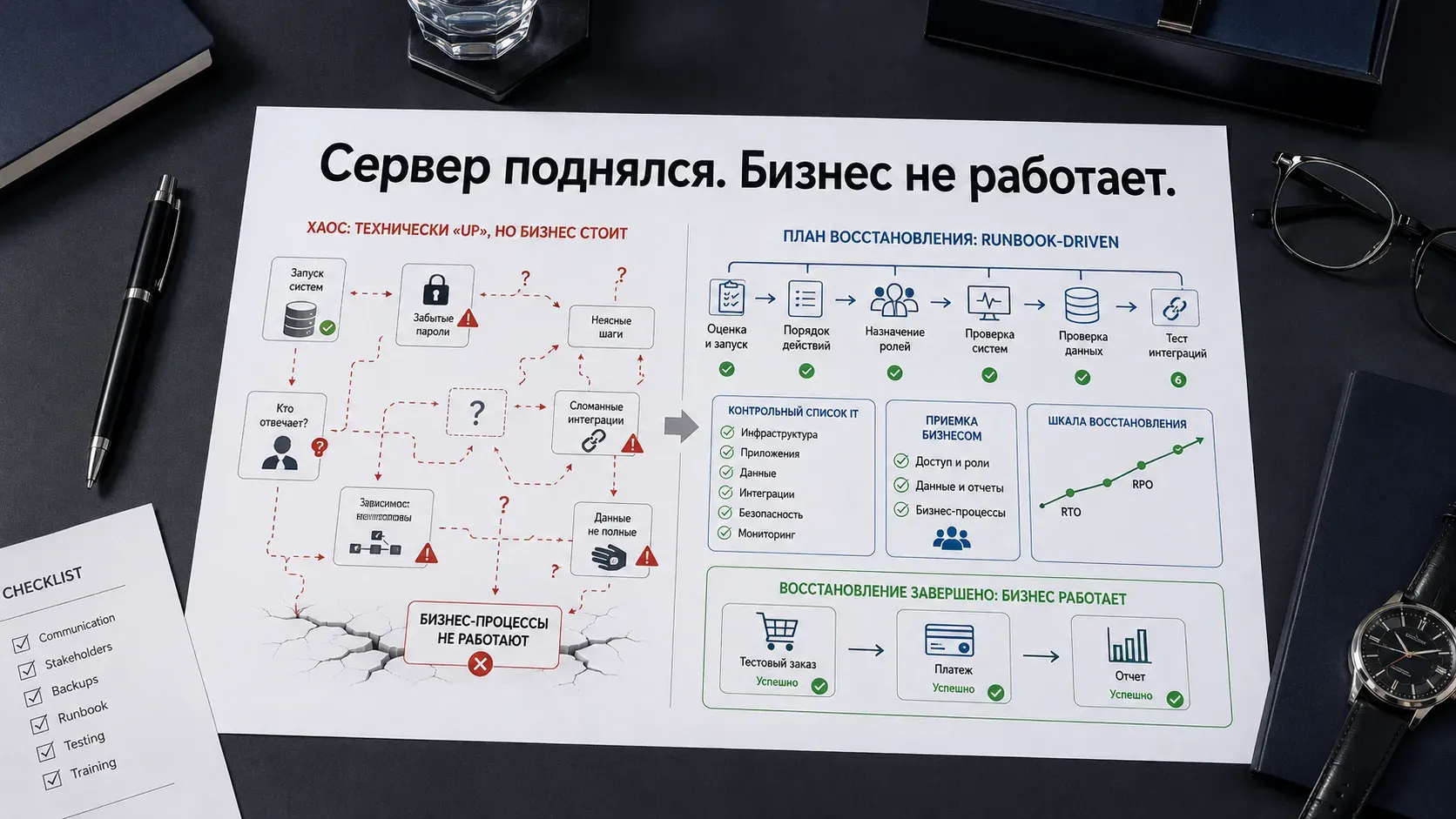
Первый тест мы провалили. Технически система поднялась. Продажи не принимались. Склад работал с данными на час раньше текущего момента. Интеграции - часть сломана, часть живёт в своём мире. Технический результат был. Бизнес-результата не было.
Это не технический провал. Это отсутствие runbook.
В одном из контуров мы потом довели DR до понятного результата: восстановление критичных сервисов менее чем за час, 0 потерь данных, SLA 100%.
Но это получилось не из-за хороших бэкапов. Это получилось после того, как восстановление перестало быть задачей ИТ и стало отрепетированным сценарием компании.
Как выглядит восстановление без плана
Я видел похожие сценарии в разных контурах. Детали отличались, но логика провала повторялась: бэкапы есть, инфраструктура есть, а восстановление всё равно превращается в ручной поиск людей, паролей, копий и последовательности действий.
Первое: не могут найти, где лежат копии. Бэкапы делались, это все знали. Где именно - знал один человек, которого нет на месте. Начинают звонить. Первые двадцать минут уходят на это.
Второе: восстанавливают не ту копию. Нашли хранилище, нашли файлы, взяли ближайший по дате. Подняли. Через час выясняется, что это копия тестового окружения, а не продуктивного.
Третье: у нужной копии пароли, которых никто не знает. Правильная копия найдена. Но она зашифрована. Пароль есть, но в голове у человека, который в отпуске. Снова звонки, мессенджеры, ожидание.
Четвёртое: система поднялась, но часть интеграций сломалась. Те, что остались работать, подключились к данным резервной копии, а не к продуктивному контуру. Пользователи видят систему - но вводят данные не туда. Это обнаруживается не сразу.
Итог: сервер включён через три часа. Бизнес не работает ещё через два. Причина - никто заранее не договорился, кто, что и в каком порядке делает.
Сервер включён. Бизнес не работает.
Этот разрыв стоит назвать прямо.
Технический критерий восстановления: сервер отвечает, сервис запущен, нет ошибок в логах. ИТ может считать задачу выполненной.
Управленческий критерий восстановления: можно принять заказ, провести платёж, получить актуальный остаток на складе, сформировать отчёт. Бизнес может работать.
Между этими двумя точками - зона, где всё ещё может пойти не так. Интеграции между системами. Переключение с резервного контура на продуктивный. Актуальность данных. Доступы пользователей. Каждый из этих шагов требует отдельной проверки.
DR заканчивается не ping. DR заканчивается контрольным заказом, чеком или отчётом.
Если контрольный сценарий не пройден, восстановление не завершено. Даже если все серверы уже зелёные.
Что должно быть в runbook
Runbook - это не инструкция для ИТ. Это совместный план компании на случай сбоя. Его цель - сделать восстановление предсказуемым: каждый шаг известен, каждый ответственный назван, каждая проверка зафиксирована.
Пять блоков, без которых план не работает.
Кто объявляет аварию и запускает процесс. Один человек. Не коллегиальное решение, не обсуждение в чате. Один ответственный принимает решение: "это авария, начинаем процедуру". Без этого первые минуты уходят на согласование того, насколько всё серьёзно.
Порядок запуска систем. Критичные контуры - первыми. Последовательность зафиксирована заранее и не обсуждается в момент инцидента. Порядок принципиален: одни системы зависят от других. Поднять не в той последовательности - получить ошибки интеграций даже при технически успешном восстановлении.
Контрольные проверки ИТ. После каждой системы - чек-лист. Не ощущение что "всё работает", а конкретные проверки: сервис запущен, интеграции активны, данные актуальны на нужный момент времени, доступы работают. Чек-лист не меняется от инцидента к инциденту.
Бизнес-приёмка. От каждого ключевого направления заранее назначен ответственный за бизнес-приёмку. Не наблюдатель и не случайный пользователь, а человек, который имеет право сказать: направление работает. Без этого ИТ закрывает инцидент, но бизнес продолжает работать в нештатном режиме.
Коммуникации. Кто, когда и что сообщает CEO и руководителям направлений. Два момента: при начале восстановления - "авария зафиксирована, процедура запущена, горизонт X часов". При завершении - "восстановление завершено, бизнес-приёмка пройдена". Руководители не должны узнавать о ходе событий из слухов или сами звонить в ИТ.
Кто принимает восстановление
Это самый управленческий момент всего процесса.
ИТ проходит по своему чек-листу. Это их профессиональная ответственность, и они с ней справляются. Но "ИТ проверил" не равно "бизнес может работать".
От каждого ключевого направления заранее назначен ответственный за бизнес-приёмку. Не наблюдатель и не случайный пользователь, а человек, который имеет право сказать: направление работает. Он знает, что именно нужно сделать: провести тестовую транзакцию, проверить актуальность остатков, сформировать контрольный документ.
Восстановление считается завершённым только после этого вердикта. Не после того, как ИТ закрыл задачу.
Этот момент меняет управленческую логику. Бизнес перестаёт быть наблюдателем и становится участником процесса восстановления. А значит, несёт за него ответственность.
Регулярные тесты: организационная дисциплина
Runbook без тестов - это документ, а не процесс.
Ежемесячные тесты для критичных систем. Ежеквартальные - для остальных. Каждый тест: реальное восстановление из реальной копии в контрольной среде с прохождением всех пяти блоков runbook и финальной бизнес-приёмкой.
В этом случае сопротивления не было. Люди уже сталкивались с потерей данных и хорошо понимали, зачем нужна тренировка. Тесты воспринимались не как нагрузка, а как защита себя.
После каждого теста - разбор: что не сработало, что заняло больше времени, что нужно обновить в runbook. Тест без разбора - упущенная возможность улучшить план до следующего инцидента.
У runbook тоже есть цена
Runbook не бесплатен в сопровождении.
Его нужно обновлять после каждого существенного изменения в системах. Проверять после релизов - вдруг что-то из плана уже не актуально. Переназначать ответственных после смены людей в команде. И реально прогонять на тестах, а не просто хранить в папке.
Если этого не делать - через полгода runbook снова превращается в красивый файл, который описывает системы и людей, которых уже нет. Инцидент снова начнётся с нуля.
Решение рабочее. Но у него есть цена: постоянная дисциплина актуализации.
Цена отсутствия плана
Без runbook каждый инцидент начинается с нуля.
Кто звонит первым? Кто принимает решение, что это авария? Где копия? Какие пароли? В каком порядке поднимать? Кто проверяет, что всё работает?
Эти вопросы решаются в реальном времени, под давлением, когда бизнес уже стоит. Именно в этот момент выясняется, что ответственный уволился, пароль сменили три месяца назад, а инструкция описывает систему, которой уже нет.
Для бизнеса это не "плюс два часа восстановления". Это два часа без заказов, отгрузок, платежей, актуальных остатков и нормального управленческого решения.
Для собственника это не ИТ-инцидент. Это остановка денежного контура: заказы не принимаются, отгрузки не подтверждаются, остатки спорные, управленческие решения принимаются вслепую. И чем дольше компания выясняет, кто за что отвечает, тем больше авария превращается из технической проблемы в прямую операционную потерю.
Время восстановления в этом сценарии непредсказуемо. Не из-за плохого оборудования или слабой команды. А потому что каждая минута уходит не на восстановление - а на выяснение того, что делать дальше.
Для CEO
DR-инфраструктура - это техническая готовность. Runbook - это управленческая готовность. Одно без другого не работает.
Бэкапы могут быть в порядке. ЦОД может работать. Репликация может идти каждый час. И при этом восстановление займёт непредсказуемое время - потому что техническая готовность не была превращена в управленческий сценарий.
Один вопрос, который стоит задать прямо сейчас: если завтра в 9 утра упадёт критичная система - кто через пять минут уже знает, что делать? Не "кто побежит разбираться". А кто уже знает, потому что репетировал этот сценарий.
Восстановление менее чем за час начинается не в момент сбоя. Оно начинается в тот день, когда компания впервые репетирует этот час на живом сценарии.
Следующий материал - про то, что происходит с данными во время восстановления. Потому что "система работает" и "данные целы" - это два разных вопроса.
#cio #итибизнес